Trans-N (Tokyo, Japan; CEO: Harry Na), has released Swama, an open-source platform that enables lightweight and high-speed local execution of large language models (LLMs) on macOS.
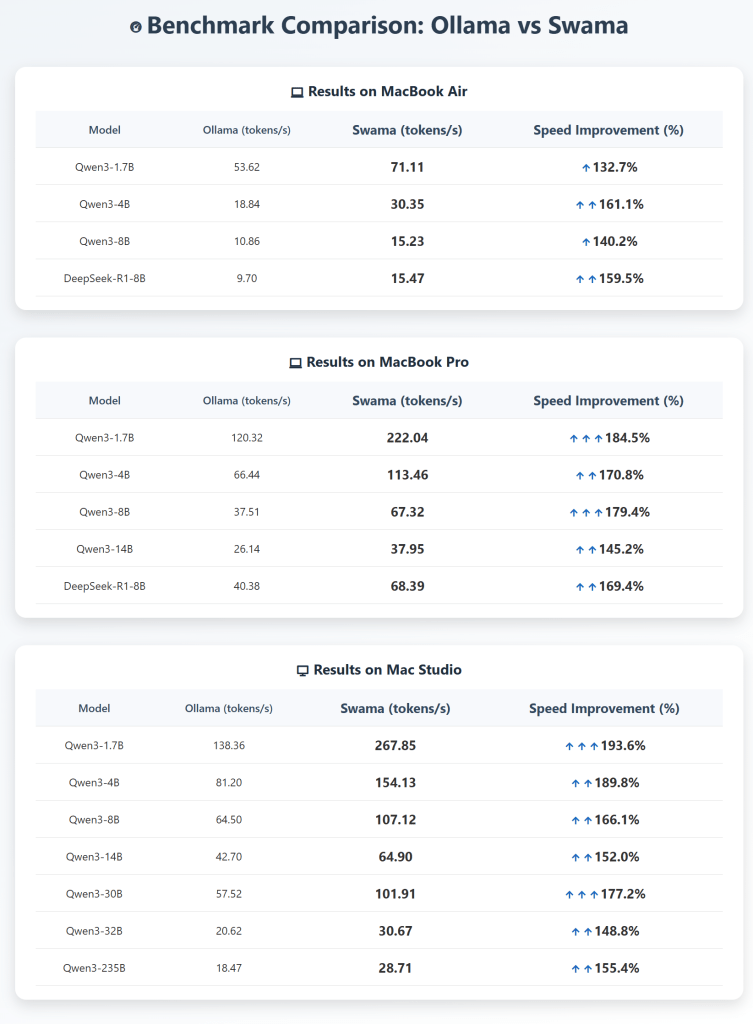
To optimize the most widely used local LLM runtime, Ollama, for macOS, Swama was built entirely from scratch using Apple’s native technologies—the Swift programming language and the MLX machine learning framework developed by Apple. Leveraging Apple’s native stack has allowed Swama to achieve significant performance improvements. In benchmark tests across various Mac models, Swama demonstrated approximately 1.5 to 2.0 times faster processing speeds compared to the baseline performance of Ollama. *
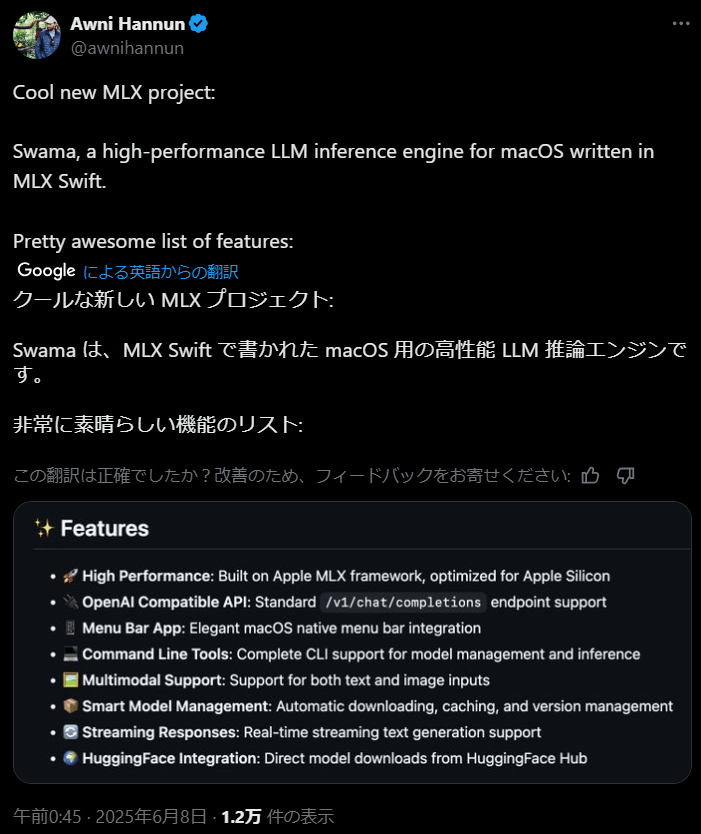
Swama has been highly praised by Awni Hannun, a machine learning research scientist at Apple with over 26,000 citations to his academic work, following its release.
*Evaluation metric – tokens/s: A “token” is the basic unit used by language models to understand and generate text. Tokens per second (tokens/s) indicates how many tokens can be processed per second; the higher the value, the greater the processing capability.
Key features of Swama – Why it delivers the best local AI experience on Mac
- Built entirely in the native language of macOS
Developed exclusively in Swift, Apple’s native programming language, Swama is finely tuned for Mac, delivering raw, uncompromised speed. - Fully leverages Apple’s AI engine
Swama harnesses MLX, Apple’s machine learning framework, to accelerate AI computation by utilizing the Mac’s CPU, GPU, and Neural Engine simultaneously. - Compatible with OpenAI APIs
Swama supports the same API endpoints as OpenAI (e.g., /v1/chat/completions), enabling seamless integration into existing toolchains for RAG and chat applications—just change the settings. - Handles both text and images
Swama goes beyond text generation—it can also interpret and respond to images, offering a rich, all-in-one generative AI experience on a single Mac.
Comment from the Head of Engineering
Previous GPU-dependent products were too slow for LLM inference on Mac and failed to meet our functional requirements. That’s why we rebuilt everything from the ground up using Swift and MLX, drawing on the expertise we gained through developing our integrated hardware platform ‘N-Cube’, based on Mac Studio.Swama’s CLI and API interface allows seamless integration into existing workflows—while achieving 1.5 to 2 times the speed of Ollama on its own. By open-sourcing the platform, we aim to accelerate generative AI development within the Apple ecosystem and bring high-performance local AI experiences to more users.
— Xingyue Sun, Head of Engineering, Trans-N
One response to “Trans-N releases “Swama”, a locally optimized LLM execution platform for macOS”
[…] Locally Optimized LLM Execution Platform for macOS" | /2025/06/12/250612-2/Official announcement and documentation for Swama, covering features, performance metrics, and setup […]